- Topic1/3
98 Popularity
22k Popularity
4k Popularity
4k Popularity
170k Popularity
- Pin
- Hey fam—did you join yesterday’s [Show Your Alpha Points] event? Still not sure how to post your screenshot? No worries, here’s a super easy guide to help you win your share of the $200 mystery box prize!
📸 posting guide:
1️⃣ Open app and tap your [Avatar] on the homepage
2️⃣ Go to [Alpha Points] in the sidebar
3️⃣ You’ll see your latest points and airdrop status on this page!
👇 Step-by-step images attached—save it for later so you can post anytime!
🎁 Post your screenshot now with #ShowMyAlphaPoints# for a chance to win a share of $200 in prizes!
⚡ Airdrop reminder: Gate Alpha ES airdrop is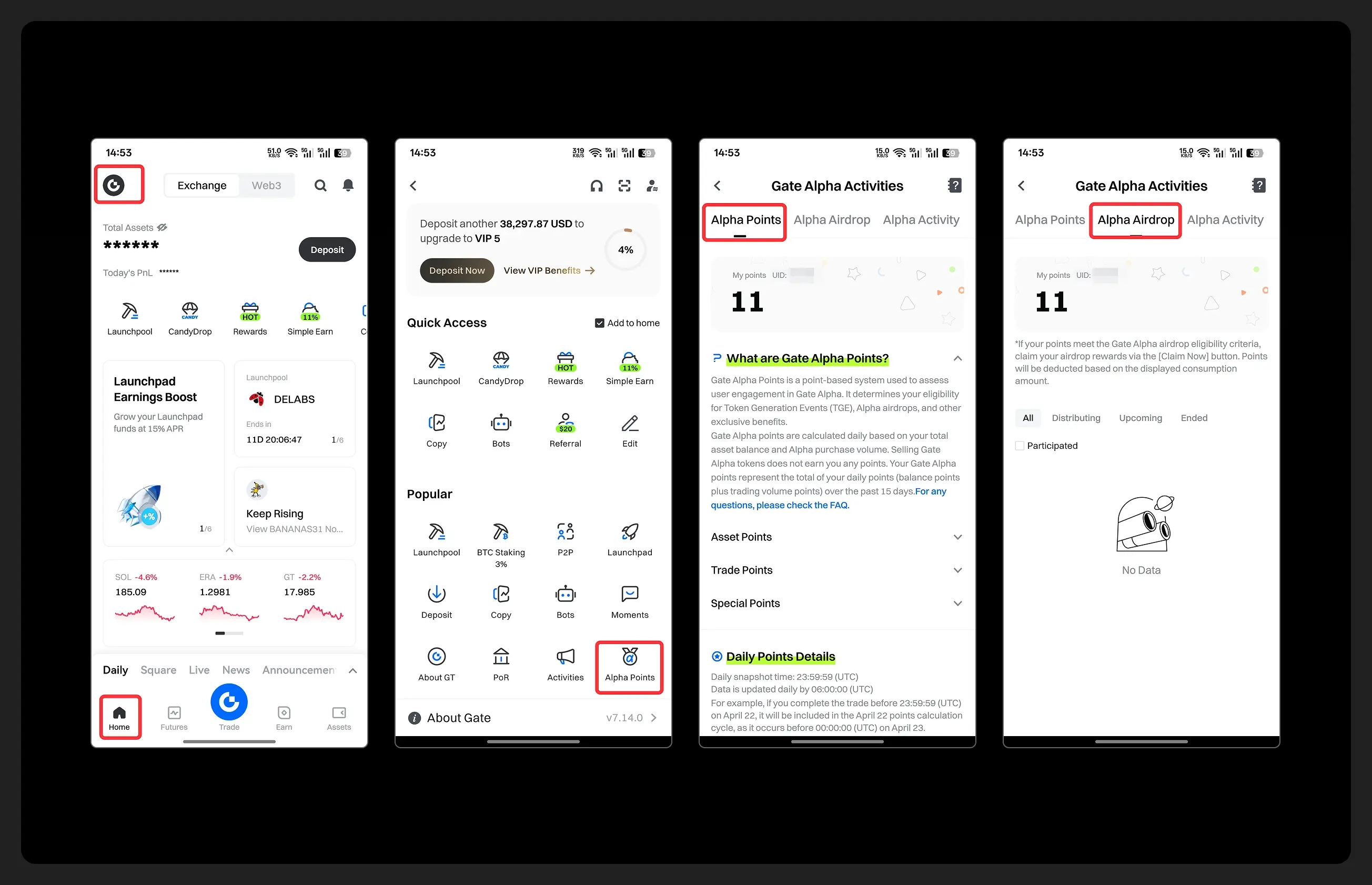
- Gate Futures Trading Incentive Program is Live! Zero Barries to Share 50,000 ERA
Start trading and earn rewards — the more you trade, the more you earn!
New users enjoy a 20% bonus!
Join now:https://www.gate.com/campaigns/1692?pid=X&ch=NGhnNGTf
Event details: https://www.gate.com/announcements/article/46429
- Hey Square fam! How many Alpha points have you racked up lately?
Did you get your airdrop? We’ve also got extra perks for you on Gate Square!
🎁 Show off your Alpha points gains, and you’ll get a shot at a $200U Mystery Box reward!
🥇 1 user with the highest points screenshot → $100U Mystery Box
✨ Top 5 sharers with quality posts → $20U Mystery Box each
📍【How to Join】
1️⃣ Make a post with the hashtag #ShowMyAlphaPoints#
2️⃣ Share a screenshot of your Alpha points, plus a one-liner: “I earned ____ with Gate Alpha. So worth it!”
👉 Bonus: Share your tips for earning points, redemption experienc
- 🎉 The #CandyDrop Futures Challenge is live — join now to share a 6 BTC prize pool!
📢 Post your futures trading experience on Gate Square with the event hashtag — $25 × 20 rewards are waiting!
🎁 $500 in futures trial vouchers up for grabs — 20 standout posts will win!
📅 Event Period: August 1, 2025, 15:00 – August 15, 2025, 19:00 (UTC+8)
👉 Event Link: https://www.gate.com/candy-drop/detail/BTC-98
Dare to trade. Dare to win.
Easily speed up your LLMs by up to 3x⚡️while preserving over 99.5% model accuracy 🎯
With TensorRT Model Optimizer's Post-Training Quantization, you can quantize state-of-the-art models to NVFP4—significantly reducing memory and compute overhead during inference, while